
CISC 6000: Deep Learning
深度学习作业代写 Build a new model Mf inal by integrating both batch normalization and the best dropout rate to your baseline model Mbase. Train your
1. Convolutional Neural Network (50 points) 深度学习作业代写
In this exercise, we will practice building CNN models to classify images from a subset of the CIFAR-10 dataset (https://www.cs.toronto.edu/~kriz/cifar.html). The following files are provided for this exercise in KCE and Blackboard:
• cifar_train.npy: 48000 pics in numpy array, each of size 32 × 32 × 3
• cifar_train_label: 48000 corresponding labels
• cifar_test.npy: 12000 test images
• cifar_test.label: 12000 corresponding labels
• sample_submission.csv: sample output to be submitted in KCE
Deliverables:
(a) For an input feature map of size 64 × 64 × 16, compute the number of multiplications and output size after the following convolution(s):
i. Using 32 3x3 kernels with stride = 1, padding = “same”.
ii. Using two consecutive convolutions: first apply 5 1 × 1 kernels, and then apply 32 3 × 3 kernels. Both with stride = 1, padding = “same”.
(b) Implement and train your baseline model Mbase using the following specifications: 深度学习作业代写
• Use 20% of your data for validation
• Your model will have 3 convolutional layers
• Number of filters for the convolutional layers are 16, 32, 48 respectively
• Maxpooling (2 x 2) following the first two convolutional layers
• Two fully connected layers of size 500 and 10 respectively
• Padding = same, kernel size = 3, stride = 1.
• Training: epoch = 80, batch size = 128, learning rate = 0.001, optimizer = Adam, activation = ReLU
i. Present your model’s summary.
ii. Save your best (hint: use ModelCheckpoint callback) Mbase in hdf5 format and plot the learning curve of Mbase.
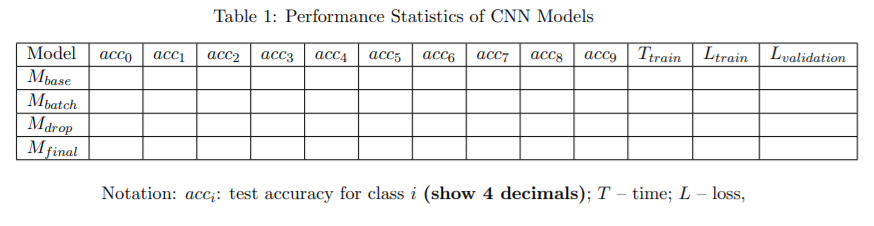
iii. Fill in Row #1 in Table 1.
(c) Build a new model Mbatch by adding batch normalization to your baseline model Mbase. Train your model with the same parameters specified in (b) and save the best model. 深度学习作业代写
i. Plot the learning curves of Mbase and Mbatch in one graph.
ii. Fill in Row #2 in Table 1.
(d) Build a new model Mdrop by adding dropout to your baseline model Mbase. Select a dropout rate p ∈ {0.1, 0.2, 0.3, 0.4, 0.5}, and set p amount of units to zero for each hidden layer. Train your model with the same parameters specified in (b) and save the best model.
i. What is the best dropout rate for your model measured by the overall prediction accuracy? Show your work.
ii. Plot the learning curves of Mbase and Mbatch and Mdrop in one graph.
iii. Fill in Row #3 in Table 1
(e) Build a new model Mf inal by integrating both batch normalization and the best dropout rate to your baseline model Mbase. Train your model with the same parameters specified in (b) and save the best model.
i. Plot the learning curves of Mbase and Mbatch, Mdrop and Mf inal in one graph. 深度学习作业代写
ii. Fill in Row #4 in Table 1.
2. Convolutional Autoencoder (50 points)
In this exercise, we will implement a convolutional denoising autoencoder (AE) to correct salt-and-pepper noise in images. Figure 1 illustrates samples of original images, noisy input and desired autoencoder output.
Figure 1: Samples of Original Images, Noisy Input and Desired Autoencoder Output

The following files are provided for this exercise in KCE and Blackboard:
(I) train_clean_data.zip: 30K clean images 深度学习作业代写
(II) train_noisy_data.zip: 30K corresponding noisy images with salt-and-pepper noise
(III) test_clean_data.zip: 20K clean images
(IV) test_noisy_data.zip: 20K corresponding noisy images with salt-and-pepper noise
(V) labels_csv: 20K labels for images in (III) and (IV)
(VI) M_weights_hdf5: pre-trained weights of a classification model M
Deliverables 深度学习作业代写
(a) Implement and train your AE using the images in (I) train_clean_data.zip and
(II) train_noisy_data.zip. You are free to design your own AE with the followingconstraints:
• Your AE should NOT contain any fully connected layer
• Your encoder should have 3 hidden layers
• Kernel size can be k × k where k ∈{1, 2, 3, 4, 5}
• For each convolutional layer, number of filters can be n where n ∈ {16, 24, 32, 40}
• Optional maxpooling layers
• Your latent vector (i.e., ”bottleneck layer”) should have size = 64
• Total number of parameters should be under 80,000
• Your can set your hyper-parameters on your own. 深度学习作业代写
i. Present your model’s summary.
ii. Present your best model’s training time, training loss, validation loss, and test loss.
Note: your model’s validation loss should be less than 0.55.
iii. Applied your trained AE model to images in (IV) test_noisy_data.zip. Plot first 10 images, their latent vectors (in 8 by 8 pixels) and corresponding output images in your ipython notebook in KCE, as illustrated in Figure 2.

(b) To demonstrate the efficacy of an AE model, we have trained a classification model M on clean MNIST images of the same input dimension as those in this exercise. Weights for M are provided in the file (VI) M_weights_hdf5.
i. Loading the pre-train weights into model M and apply M to data in
(III) test_clean_data.zip and (IV) test_noisy_data.zip respectively. Fill in the first two corresponding rows in Table 2.
ii. Create a new integrated model such that the output of AE will be the input to M.
Apply this new model to (III) test_clean_data.zip and (IV) test_noisy_data.zip again, and fill in the corresponding rows in Table 2.
Table 2: Performance Statistics of AE + Classification Model 深度学习作业代写




发表回复
要发表评论,您必须先登录。