
ITP-449 Applications of Machine Learning
机器学习代考 Your task is to build a classification model that predicts the edibility of mushrooms (class variable in the dataset). You have been
Definition/Description 机器学习代考
The final project for this course entails four (4) distinct questions using four (4) distinct datasets. You will be using several of the ML algorithms that have been covered over the course of the course: KNN, Classification Trees, and Linear Regression.
Question 1: Wine Quality Classification Using KNN
The goal of this Question is to predict the quality of wine given the other attributes.
- Loadthedata from the file winequality.csv. (2)
- Standardizeallvariables other than Quality. (2)
- Partition the dataset (3) 机器学习代考
- Build a KNN classification model to predict Quality based on alltheremaining numeric variables. (2)
- a. random_state = 2020, Partitions 60/20/20, stratify = y
- IterateonK ranging from 1 to 30. Plot the accuracy for the train A and train B datasets. (4)
- Which value of k producedthebest accuracy in the train A and train B data sets? (2)
- Generate predictions for the test partition with the chosen value of k. Plot the confusion matrix ofthe actualvs predicted wine quality. (4)
- Print the accuracy of model on the test dataset. (2)
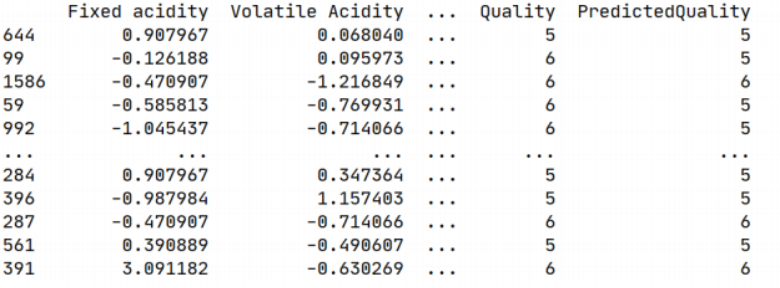
- Print the test dataframe with the added columns “Quality” and “Predicted Quality” (4)
Question 2: Personal Loan Prediction Using Trees 机器学习代考
Load the “UniversalBank.csv". This dataset is taken from the website of the book "Data mining for business intelligence" by Shmueli, Patel and Bruce, 1st ed, Wiley 2006. The data set provides information about many people and our goal is to build a model to classify the cases into those who will accept the offer of a personal loan and those who will reject it. In the data, a zero in the Personal Loan column indicates that the concerned person rejected the offer and a one indicates that the person accepted the offer. Answer the following questions:
- Whatisthe target variable? (2)
- Ignorethevariables Row and Zip code. (3)
- Partitionthedata 70/30. Random_state = 2020, stratify=y (3)
- Howmanyof the cases in the training partition represented people who accepted offers of a personal loan? (3)
- Plot the classification tree Use entropycriterion. Max_depth= 5, random_state = 2020. (4)
- Onthetraining partition, how many acceptors did the model classify as non-acceptors? (3)
- Onthetraining partition, how many non-acceptors did the model classify as acceptors? (3)
- Whatwasthe accuracy on the training partition? (2)
- Whatwasthe accuracy on the test partition? (2)
Question 3: Mushroom Edibility Using Trees
Your task is to build a classification model that predicts the edibility of mushrooms (class variable in the dataset). You have been provided with a dataset as a mushrooms.csv file. Attribute description:
- cap-shape: bell=b,conical=c,convex=x,flat=f, knobbed=k,sunken=s
- cap-surface: fibrous=f,grooves=g,scaly=y,smooth=s
- cap-color:brown=n,buff=b,cinnamon=c,gray=g,green=r, pink=p,purple=u,red=e,white=w,yellow=y
- bruises?: bruises=t,no=f
- odor: almond=a,anise=l,creosote=c,fishy=y,foul=f, musty=m,none=n,pungent=p,spicy=s
- gill-attachment: attached=a,descending=d,free=f,notched=n 机器学习代考
- gill-spacing: close=c,crowded=w,distant=d
gill-size: broad=b,narrow=n
- gill-color: black=k,brown=n,buff=b,chocolate=h,gray=g, green=r,orange=o,pink=p,purple=u,red=e,white=w,yellow=y
- stalk-shape: enlarging=e,tapering=t
- stalk-root: bulbous=b,club=c,cup=u,equal=e, rhizomorphs=z,rooted=r,missing=?
- stalk-surface-above-ring: fibrous=f,scaly=y,silky=k,smooth=s
- stalk-surface-below-ring: fibrous=f,scaly=y,silky=k,smooth=s
- stalk-color-above-ring: brown=n,buff=b,cinnamon=c,gray=g,orange=o, pink=p,red=e,white=w,yellow=y
- stalk-color-below-ring: brown=n,buff=b,cinnamon=c,gray=g,orange=o, pink=p,red=e,white=w,yellow=y
- veil-type: partial=p,universal=u
- veil-color: brown=n,orange=o,white=w,yellow=y 机器学习代考
- ring-number: none=n,one=o,two=t
- ring-type: cobwebby=c,evanescent=e,flaring=f,large=l, none=n,pendant=p,sheathing=s,zone=z
- spore-print-color: black=k,brown=n,buff=b,chocolate=h,green=r, orange=o,purple=u,white=w,yellow=y
- population: abundant=a,clustered=c,numerous=n, scattered=s,several=v,solitary=y
- habitat: grasses=g,leaves=l,meadows=m,paths=p, urban=u,waste=w,woods=d
- class: p = poisonous, e=edible
Buildaclassification tree. Random_state =2020. Training partition 0.7. stratify = y, max_depth = 6, use Entropy 机器学习代考
- Print the confusion matrix. Also visualizetheconfusion matrix using plot_confusion_matrix from sklearn.metrics (5)
- Whatwas the accuracy on the training partition? (2)
- Whatwasthe accuracy on the test partition? (2)
- Showtheclassification tree. (4)
- Listthetop three most important features in your decision tree for determining toxicity. (6)
- Classify the following mushroom. (6)
| class | ? |
| cap-shape | x |
| cap-surface | s |
| cap-color | n |
| bruises | t |
| odor | y |
| gill-attachment | f |
| gill-spacing | c |
| gill-size | n |
| gill-color | k |
| stalk-shape | e |
| stalk-root | e |
| stalk-surface-above-ring | s |
| stalk-surface-below-ring | s |
| stalk-color-above-ring | w |
| stalk-color-below-ring | w |
| veil-type | p |
| veil-color | w |
| ring-number | o |
| ring-type | p |
| spore-print-color | r |
| population | s |
| habitat | u |
Question 4: Vehicle MPGs Using Linear Regression
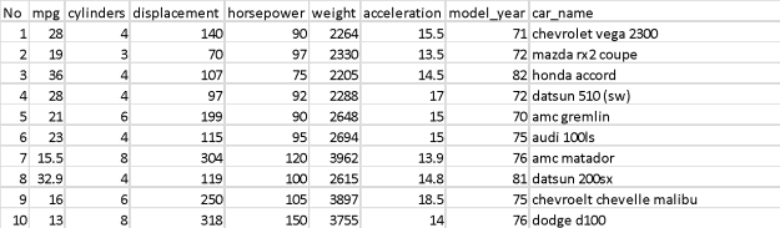
Load the data from the file auto-mpg.csv. The file contains information about various cars made between 1970 and 1982. The file contains 398 rows of data. The table below shows an extract of the first 10 rows to give you an idea of the data.
- Summarize the data set. What is the mean of mpg? (2)
Whatisthe median value of mpg? (1) 机器学习代考
- Which value is higher – mean or median? What does this indicate in terms of the skewnessofthe attribute values? Make a plot to verify your answer. (2)
- Plot the pairplot matrix of all the relevant numeric attributes. (don’t consider Noandcar_name)? (2)
- Based on the pairplotmatrix, whichtwo attributes seem to be most strongly linearly correlated? (2)
- Basedonthe pairplot matrix, which two attributes seem to be most weakly correlated. (2)
- Produce a scatterplot of the two attributes mpg and displacement with displacement on the x axis andmpgon the y axis. (2)
- Build a linear regressionmodelwith mpg as the target and displacement as the predictor. Answer the following questions based on the regression model.
- a. Foryourmodel, what is the value of the intercept β0 ? (1)
- b. Foryourmodel, what is the value of the coefficient β1 of the attribute displacement? (1)
- What is the regression equation as perthemodel? (2)
- Foryourmodel, does the predicted value for mpg increase or decrease as the displacement increases? (2)
- Given a car withadisplacement value of 220, what would your model predict its mpg to be? (2)
- Display a scatterplotofthe actual mpg vs displacement and superimpose the linear regression line. (2)
- g. Plottheresiduals. (2)
Structural Requirements
- The primary entrypoint for your code should be through main ():
def main ():
# your code goes here
and that to call it, you should use the following:
if __name__ == 'main':
main ()
- Remembertoprovide a header at the top of your code which includes:
# [Your Full Name]
# ITP-449 [Semester]
# Final Project
- Don't forgettoprovide useful comments throughout!
Provided files/data 机器学习代考
Four files will be required:
Example Output
Deliverables
You should have only one Python file, which should be named:
ITP-449_Final_Project_LastName_FirstName.py
csvs/
winequality.csv
UniversalBank.csv
mushrooms .csv
auto-mpg.csv
Compress it in a zip file, which should be named:
ITP-449_Final_Project_LastName_FirstName.zip
Submit this file on Blackboard. Assignments will only be accepted through Blackboard.
Grading
| Section | Points (Total: 100) |
| Question 1 1. | (1.0 points each) |
| Question 2 1. | (1.0 points each) |
| Question 3 1. | (1.0 points each) |
| Question 4 1. | (1.0 points each) |
| Code 1. Correct setup of main () function. 2. Correct use of call of main (). | 1.0 (1.0 points each) |
| Documentation and Formatting 1. Concise and useful commenting in your codebase is a must. You will need a header with your name, the semester, the section of the course you are in, and the homework number. 2. You need descriptions of any major sections in your code (functions, classes, methods, et al.). 3. Your code must be generally clear and readable. | 3.0 (3.0 points each) |
| Error Handling 1. Program runs without crashing. 2. Program prompts the user to re-enter inputs which are not acceptable. | 1.0 (0.5 points each) |



发表回复
要发表评论,您必须先登录。