

Part 1: Data Analysis using PySpark
PySpark作业代写 This is similar to question 2. We first collected how many data points (datapoints) grouped by UserID and Date. Then we filtered
Question 1: Data Cleaning PySpark作业代写
I first concatenated two columns Date and Time into one column and transformed it to UTC_Timestamp with the timezone set to GMT, then by modifying the timezone info for the UTC_Timestamp into Asia/Shanghai, I got the correct date and time for Beijing time. The Timestamp column is manually adjusted.
The final output is:

Question 2 PySpark作业代写
This is done via the spark_session.sql interface with a query for distinct Dates grouped by UserID.
The final output is:

Question 3
This is similar to question 2. We first collected how many data points (datapoints) grouped by UserID and Date. Then we filtered by datapoints >=100 and count the distinct Date again. The final output is:

Question 4 PySpark作业代写
This is done with spark_session.sql interface, with the query being:
select UserID, max(Altitude) as max_altitude from data group by UserID order by max_altitude desc
The results are:

Question 5 PySpark作业代写
This is done with spark_session.sql interface, with the query being:
person_timespan = spark_session.sql(
"""
select UserID,
min(Timestamp) as min_timestamp,
max(Timestamp) as max_timestamp, PySpark作业代写
max(Timestamp) - min(Timestamp) as span
from data group by UserID order by max_timestamp desc
""")
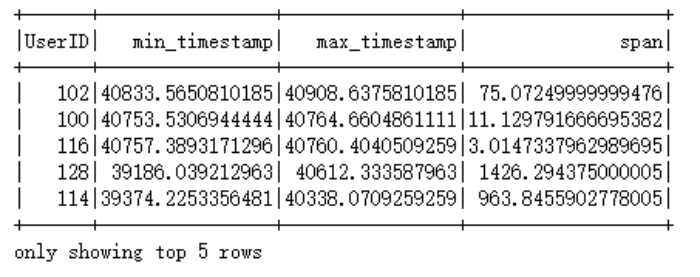
The span is measured in days. PySpark作业代写
Question 6
The calculation is done with lag and window. The geopy.distance.distance function is mapped into a UDF for spark to use.
Calculate for each person, the distance travelled by them each day
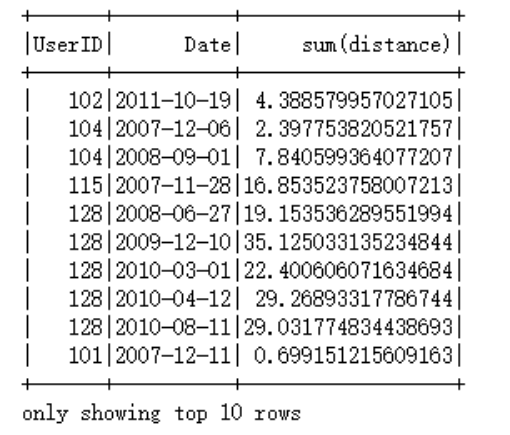
For each user output the (earliest) day they travelled the most PySpark作业代写
For each user output the total travelled distance


更多代写:cs代写 计量经济代考 机器学习代写 r语言代写 数学finalExam代考


发表回复
要发表评论,您必须先登录。