
Dataset.
Cs计算机代考 we will use the datasets generated inProblem1.) You need to try several selections for the fixed step size (or learning rate)
In this programming homework, we will use a LIBSVM dataset which are pre-processed data originally from UCI data repository.Housing dataset (We will use housing_scale dataset). Predict housing values in suburbs of Boston. Cs计算机代考
https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/regression/housing_scale.
Problem 1. Randomly split the dataset into two groups: training (around 80%) and testing (around 20%). Learn the linear regression model on the training data, using the analytic solution. Compute the prediction error on the test data: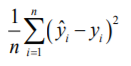 where n is the number of testing data,ˆiy and i y are the prediction and the true value respectively for data point ?. Repeat this process 10 times and report all individual prediction errors of 10 trials and the average of them.
where n is the number of testing data,ˆiy and i y are the prediction and the true value respectively for data point ?. Repeat this process 10 times and report all individual prediction errors of 10 trials and the average of them.
Problem 2. Do the same work as in the problem 1 but now using a gradient descent (10 randomly generated datasets in Problem 1 should be maintained; we will use the datasets generated in
Problem1.) You need to try several selections for the fixed step size (or learning rate). (a) Compare prediction errors with those from Problem 1; (b) Additionally, draw plots showing objective
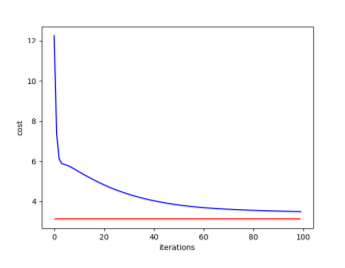
function values vs. iterations of gradient descent. In all plots, optimal objective function value by analytic solution should be presented (it would be a horizontal line, as shown in Figure below).
Report for different step sizes (for too large, proper and too small step sizes).

更多代写: cs代上网课 math网课代考 英国代写 Progress Report 代写 英国paper代写 澳洲paper代写


发表回复
要发表评论,您必须先登录。